# Race/Ethnicity
# prolific.df$race[prolific.df$Q53_1==1] <-1 #Black
# prolific.df$race[prolific.df$Q53_2==1] <-2 #White
# prolific.df$race[prolific.df$Q53_3==1] <-3 #Asian
# prolific.df$race[prolific.df$Q53_4==1] <-4 #Latino
# prolific.df$race[prolific.df$Q53_5==1] <-5 #Native Americanp
# rolific.df$race[prolific.df$Q53_6==1] <-6 #Marked otherTogether with Efrén, John Lee, and Emilio at Northwestern replication game, we looked at the “Se Habla Español: Spanish-Language Appeals and Candidate Evaluatioited States” paper and replication package. Suffered for a bit and put together a computational replication. Results held the same. See the replication report.
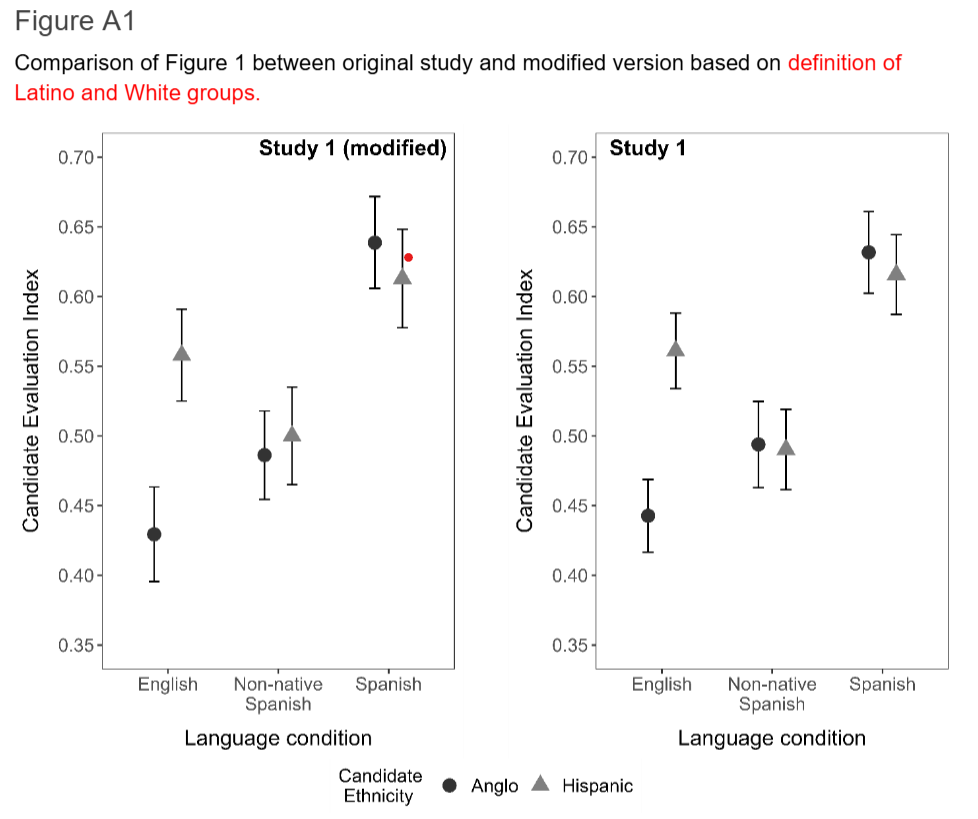
However, some of the computational representations and analytic choices were questionable. For example, my biggest concern was about the identification of participants as White and Latino. Some parts of the study relied on Prolific’s survey, which did not match the paper’s survey. While it may not have had a significant impact on the final results, one part of the code was hilariously wrong.
During data processing, we noticed that a series of questions were asked to report their ethnicity in multiple-choice questions Q53_1, Q53_2, Q53_3, Q53_4, Q53_5, Q53_6. The provided code used a unique strategy for coding race, based on exclusive self-nomination, where the last option overwrites all previous choices. For example, if a participant self-reported to be Black and White, the race column would reflect only white Race/Ethnicity. At the same time, if a participant self-reported to be Black, White and Latino then the Latino option will overwrite all previous ones.
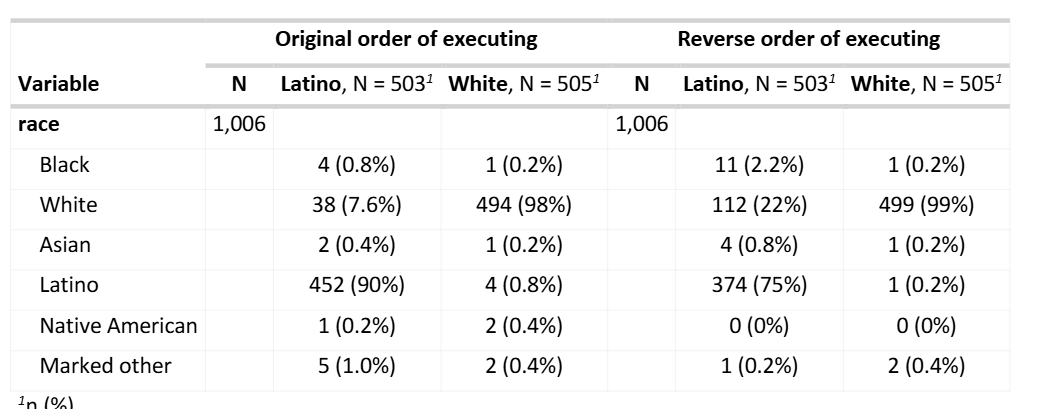
In the grand schema of things, those minor details did not matter and a good model should be replicated from a summary. However, it is always good to make sure the code makes sense.
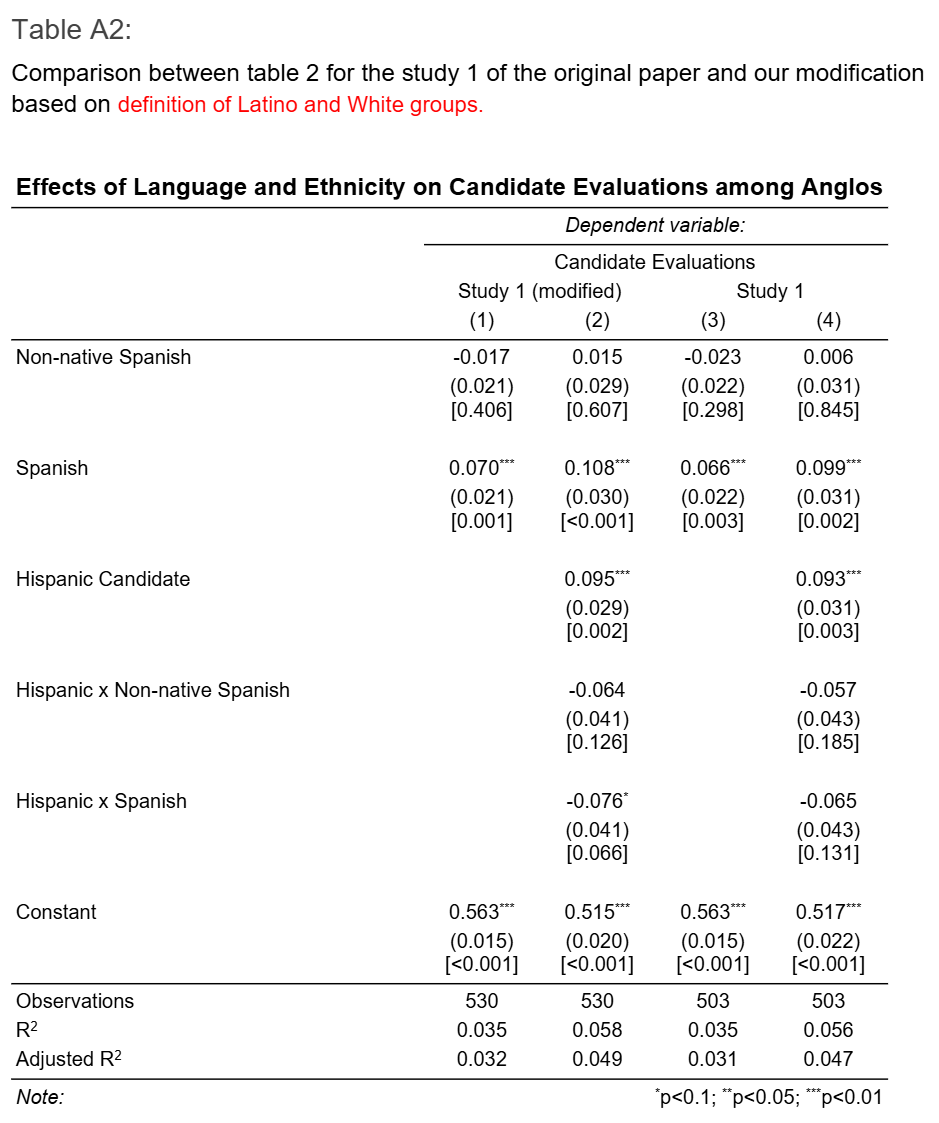
Overall, the paper is good.